Lec 00: Scratch
1. What is computer science?
- Computer science is fundamentally problem solving.
- What is problem solving is as the process of taking some
input(i.e., details about our problem), and then generate someoutput(i.e., the solution to our problem). Theblack boxin the middle is Computer Science, that is the code we'll learn to write.
- To begin doing that, we'll need a way to represent
inputandoutput, so that we can store and work with information in a standardized way.
2. Representing numbers
2.1. Unary
When we counting the number of people in a room, probably we can do it with our hand, that is we raise one finger at a time to represent each person. It's stupid but simple, and we won't be able to count very high.
This system is unary , where each digit represents a single value of one.
2.2. Decimal
As we know, we have a more efficient system to represent numbers, where we have 10 digits, 0 through 9.
0 1 2 3 4 5 6 7 8 9
This system is called decimal, or base 10, since there are 10 different values that a digit can represent.
2.3. Binary
Computer use a simpler system called binary, or base 2, with only two possible digits, 0 or 1.
Since computer run on electricity, there are two states of an electronic switch, which can be turned on or off.
We can conveniently represent a bit by turning a switch on or off to represent a 0 or 1.
3. Text
3.1. Map and ASCII
Since the computer can only represent number in binary, so if we wanna represent text or a single letter, we need to map the numbers to letters, e.g., 'A' can be mapped to 65, and 65 is a Decimal number, it's 01000001 whose representation of 65 in binary.
Fortunately, we needn't to decide the correspondences of each letter mapping. There is a standard mapping, ASCII(American Standard Code for Information Interchange), which include the mapping of higher-case, lower letters and punctuation.
3.2. one Byte = 8 Bits
E.g., If we received a text message with a pattern of bits that had a decimal values 72, 73 and 33 , those would map to the letters HI. Each letter actually is typically represented with a pattern of eight bits, or a byte.
So, the sequences of bits we would receive are 01001000, 01001001, and 00100001.
Byte is the unit of measurement for data with which we might already be familiar, as in megabytes(MB) or gigabytes(GB), for million or billions of bytes.
With eight bits, or one byte, there are 2^8^, or 256 different values (including zero), and the highest value we can count up to would be 255.
3.3. Unicode
Can we represent any characters by using one byte? We know one byte have 2^8^ different values, so one byte can represent 2^8^ = 256 characters. Of course it's more than 256 characters that the character of languages all around the world, such as Asian language, Islam language etc.
What's more, there are also other characters such as letters with accent marks and symbols.
They are part of a more generally standard called Unicode, which uses more bits than ASCII to accommodate all the characters.
Concretely, when we receive an emoji, out computer is actually receiving a number in binary that it then maps to the image of the emoji based on Unicode standard.
For example, the "face with tears of joy" emoji is just the bits 000000011111011000000010:
4. Images, video, sounds
4.1. Images
4.1.1 RGB
An image, like the picture of the emoji "face with tears of joy" above, are made up of colors. We can still represent each color with only bits, just like how we map numbers to letters, we can map numbers to colors as well.
There are many different systems to represent colors, but a common one is RGB, which represent a color by indicating the amount of red, blue and green within each color. And our programs would know those bits map to a color if we opened an image file, as opposed to receiving them in a text message(map to letters).
4.1.2 Pixels
We know that there are lots of dots in a photo if we zoom in, e.g., the emoji above:
These dots, or squares are called pixels, and image are made up of many thousands or millions of those pixels as well.
There are three bits to represent the amount of red, blue and green color in this pixel. For example, if we have received this pattern of bits: 72, 73, 33. That indicate the amount of blue is 72 over 255(a bit has 2^8^ different values ), and so on. So we'll get this eventually:
4.1.3. Resolution
The resolution of an image is the number of pixels there are, horizontally and vertically.
That means more clear image(High-resolution) we get, more pixels it'll have, and then, more bits required to be stored. That explains why the high-resolution image always need more storage.
4.2. Video
Video is a sequence of images, which changing multiple times a second to give us appearance of motion, as an old-fashioned flip-book might do.

For us human being, if the images can changing enough multiple times in a second, we cannot discriminate whether it's a sequence of image or a continuous video, with our eyes.
4.3. Sounds
Of course music can be represented with bits, with mappings of numbers to notes and durations, or more complex mappings of bits to sound frequencies at each moment of time.
4.4. Others files
File formats, like JPEG and PNG, or WORD or EXCEL documents, are also based on some standard that some humans have agreed on, for representing information with bits.
5. Algorithms
5.1. What is Algorithms
Now we can represent inputs and outputs with bits, we can concentrate our work on problem solving, where the black box in the middle of the figure before.

Algorithms are some step-by-step instructions for solving problem, it's some computings that make the input to the output what we want.
Humans can follow algorithms too, such as recipes for cooking. When programming a computer , we need to be more precise with our algorithms so that our instructions aren't ambiguous or misinterpreted.
5.2. Correct and Bug
Some of algorithms are correct, some of algorithms have bug yet.
If the algorithm is correct, we can get the output we want of the problem. Otherwise, we won't solve the problem until we fix the bug.
5.3. Time complexity
Different algorithms have different efficiencies, time complexity could show the efficiency of algorithms by counting the number of elementary operations performed by algorithm.
Concretely, think there is a problem finding someone's number in a phone book sorted alphabetically.
- Our input is the name of someone we looking for his number, and a phone book sorted alphabetically and contains his number.
- Our output is the phone number.
So, there are three algorithms with varied efficiency.
- Start from first page, search each name with its phone-number in each page, until we find it.
- Ditto, but we can find it two pages at a time, if we flipped too far, we have to check it back.
- Start from the middle page of the phone-book, decide whether our name will be in the left half or right half of the book(since our book is alphabetically), and reduce the size of our problem by half. Repeat until we find our name.
In fact, we can represent the efficiency of each of those algorithms with a chart:
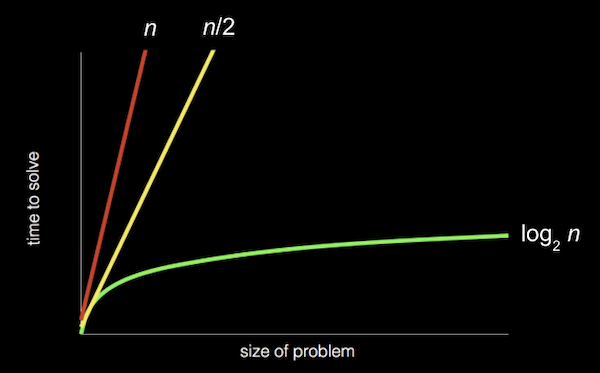
The efficiency of the third one algorithm is well over the others. That is logarithmic algorithm, since we’re divid ing the problem by two with each step.
So when we write programs using algorithms, we not only have to care about whether the algorithm is correct, but also how well-designed it is, considering factors such as efficiency.
6. Pseudocode
6.1. What is Pseudo-code
Pseudo-code by definition is not real code, but a representation of our algorithm in precise English(or some other human language u like).
Concretely, we can represent the algorithm of the phone-book problem above with pseudo-code:
With these steps we can solve the problem easily. But NOTICE that, there is a statement "Else" at line 12, this is called "final case", which is particularly important to remember, cause it might appear to freeze or stop responding when we forget it , even it can continue to repeat the same work over and over and never stop, just since the algorithm encountered a case that wasn't accounted for.
6.2. Each part of it
- Notice that some of these lines start with verbs, or actions, such as
Pick up,Open toetc. There are functions. - We also have branch that lead to different paths like
If,Else ifetc, like forks in the road, which we'll call conditions. - And there are many questions that decide where we go are called Boolean expressions, which eventually result in a value of yes(True) or no(False), as
person is on pagein line 4. - Lastly, we have words that create cycles, where we can repeat parts of our program, this called loops, as
Go back to line Nin line 8 and 11.
7. Additional features
We've found these features of programming in pseudo-code above:
- Functions
- Conditions
- Boolean expressions
- Loops
And we'll discover those additional features yet:
- Variables
- Threads
- Events
- ...etc
7.1. Hello Problem
Think of a problem that ask someone's name, and says "Hello, someone's name". The input of this problem is someone's name, and the output is "Hello," and the name.
So what's the algorithm of the problem? We can solve it in Scratch, which is a graphical programming language compared to old-fashion programming language like C, that means we can program by dragging and dropping blocks that contain instructions.
Now we can design our algorithm with pseudo-code:
Or show it with Scratch: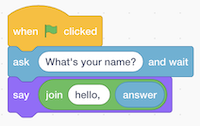
7.2. Variables
The answer block in Scratch or the name in pseudo-code is a variable, or value, that stores some values of bit which may mapping to something like numbers, letters and images etc.
In this case, this variable stores what the program's user type in, i.e., a sequence of letters of user's name.
7.3. Functions
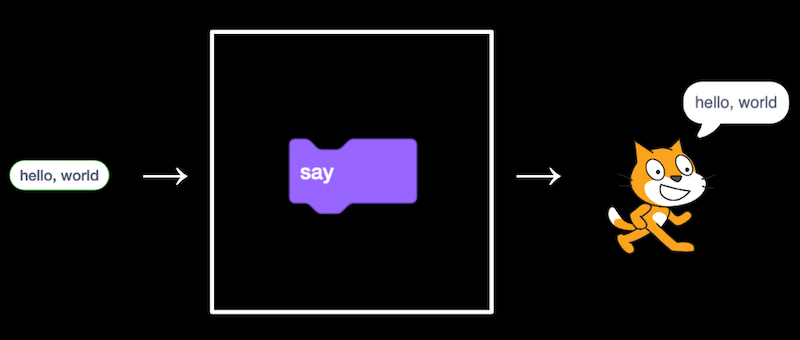
In fact, the line "Say 'hello,' ..." in line 1 or the say block itself in Scratch is like an algorithm, where we provide an input of "What's ur name" and it produced the output that to print the text of we input.
The ask block, too, takes in an input(i.e., the question we want to ask), and produces the output of a variable in that stores the name of we enter.
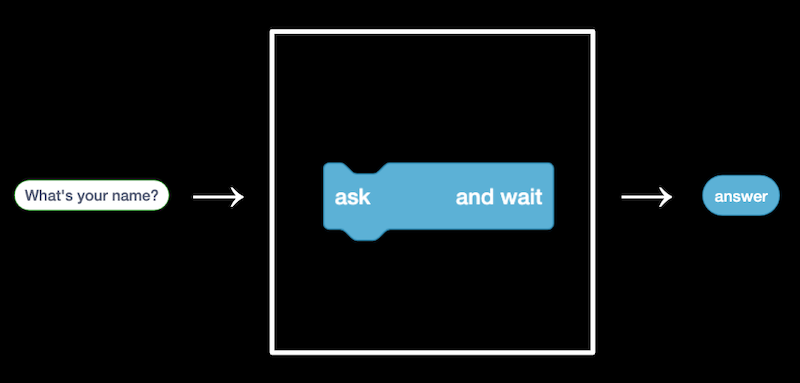
It's not limited that the number of input value, we can input multiple values to it.
E.g., we can use the answer block along with our own text, "Hello, ", as two inputs to the join algorithm(or function) :
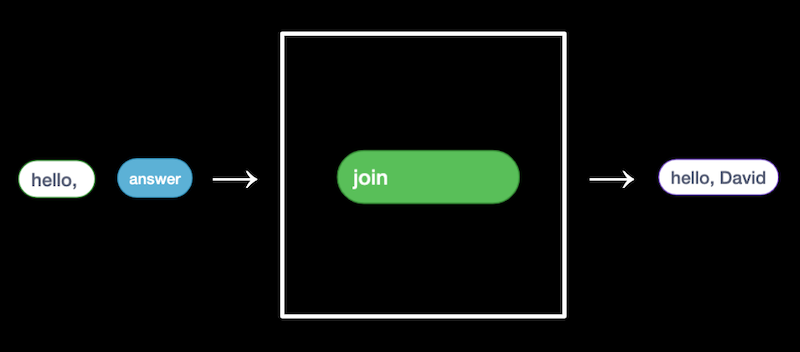
So, this is functions, which contains algorithms. It takes some input, produce some output by algorithm.
7.4. Loop
Loop is repeating something, where our programs achieves the same results, but with fewer codes, which means our code is Well-designed we mentioned before.
That because if there's something we wanna change, we would only need to change it in one place instead of lots. Besides, it'll more readable when we back to change it.
Also sometimes we need to do something forever and never ever stop it, for instance we wanna the program print the text "Hello!" forever. This time we'll need loop, but in order to repeat something never stop.
7.5. Abstraction
Abstraction is an important concept in Computer Science. What is abstraction is to simplify a more complex concept.
In case, our "Hello problem" takes some of input that the name of users', then it would produce the output that print a text of "Hello" and user's name. The algorithm of this problem is somewhat complex as we know, it contains lots of functions, which are essentially sub-problems, take some input then make some output with its algorithm. (For instance, the say function, which take words as its input, then print it as the output.)
But when we solved the hello problem, we can define it as a hello function, whose input and output is same as the problem before, but we needn't to care about how the algorithm implemented, we just use it like say function. Maybe say function contains some sub-function, just like hello function may contain say function, but whatever, who care about it.
That is Abstraction, we can focus on the higher-level of programming via abstraction. Concretely, we could reuse the solution of any problems we've done before, like hello above; or we could use the solution that anybody done, e.g., there is a function read with voice, that take the input is same as hello function's, but its output is reading the text with a human's voice.