Lec 07: SQL
1. Data processing
1.1. About Data processing
1.1.1. Spreadsheet applications
Suppose we'll collect some data about your favorite TV shows and their genres. With hundreds of responses, we can start looking at the responses on Google Sheets, a web-based spreadsheet application, showing our data in rows and columns.
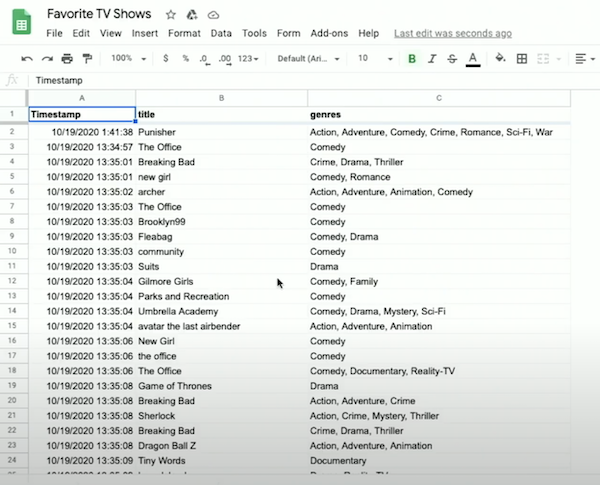
- Notice that some responses show a single genre selected, like "Comedy", while others, with multiple genres, show them in one cell but separated by a comma, like "Crime, Drama" .
With a spreadsheet application like Google sheets, Apple's Number, Microsoft Excel, or others, we can:
- Sort our data
- Store our data in rows and columns, where each additional entry is a row, and properties of each entry, like title or genre, is a column
- Decide on the schema, or format of our data in advance by choosing the columns.
1.1.2. Databases
A database is a file or program that stores data for us.
A CSV (Comma-Separated Values) file is a flat-file database where the data for each column is separated by commas, and each row is on a new line, saved simple as a file.
- If some data in a CSV file contains a comma itself, then it's usually surrounded by quotes as a string to prevent confusion.
- Formulas and calculations in spreadsheet programs are built into the programs themselves; a CSV file can only store raw, static values.
1.2. Cleaning
First, we've import our CSV file to the IDE, and we can take a look at all the unique titles in our responses using Python.
We used DictReader in csv library, dictionary reader, which creates a dictionary from each row, allowing us to access each column by its name (Since the first row in our CSV has the names of the columns, which can be used to label each column in our data as well).
Therefore we also don't need to skip the header row in this case.
We create titles as a set, which will automatically check for duplicates and ensure there are only unique values. To sort the titles, we can just change our loop to for title in sorted(titles), which will sort our set before we iterate over it.
But we'll see that our titles are considered different if their capitalization or punctuation is different, like "friends", "Friends" and "Friends " (this one has spaces at the end).
So we'll clean up the capitalization by adding title in all uppercase with titles.add(row["title"].upper()).
We'll also have to remove spaces before or after, so we can add titles.add(row["title"].strip().upper()) which strips the whitespace from the title, and then converts it to uppercase.
Now we've canonicalized, or standardized, our data, and our list of titles are much cleaner.
1.3. Counting
We can use a dictionary, instead of a set, to count the number of times we've seen each title, with the keys being the titles and the values being an integer counting the number of times we see each of them:
- Here, we first check if we’ve haven’t seen the title before (if it’s
not in titles). We set the initial value to 0 if that’s the case, and then we can safely increment the value by 1 every time. - Finally, we can print out our dictionary’s keys and values by passing them as arguments to
print, which will separate them by a space for us.
We can sort by the values in the dictionary by changing our loop to:
- We define a function,
f, which just returns the count of a title in the dictionary withtitles[title]. Thesortedfunction, in turn, will use that function as the key to sort the dictionary's elements. And we also pass inreverse=Trueto sort from largest to smallest, instead of smallest to largest.
We can actually define our function in the same line, with this syntax:
- We pass in a lambda, or anonymous function, which has no name but takes in some argument or arguments, and returns a value immediately.
1.4. Searching
We can write a program to search for a title and report its popularity:
-
We ask the user for input, and then open our CSV file. Since we’re looking for just one title, we can have one
countervariable that we increment. -
We check for matches after standardizing both the input and the data as we check each row.
The running time of this is O(n), since we need to look at every row.
2. Relational databases
2.1. What is Relational databases and SQLite
Relational databases are programs that store data, ultimately in files, but with additional data structures that allow us to search and store data more efficiently.
With another programming language, SQL (pronounced like "sequel"), Structure Query Language, we can interact with many relational databases and their tables, like spreadsheets, which store data.
We'll use a common database called SQLite, one of many available programs that support SQL. Other databases programs include Oracle Database, MySQL, PostgreSQL, and Microsoft Access.
SQLite stores our data in binary file, with 0s and 1s that represent data efficiently. We'll interact with our tables of data through a command-line program, sqlite3.
We'll run some commands to import our CSV file into a table called "shows".
-
Based on the rows in the CSV file, SQLite will create a table in our database with the data and columns.
-
We’ll set SQLite to CSV mode, and use the
.importcommand to create a table from our file.
It turns out that, when working with data, we generally need four types of operations supported by relational databases: CRUD, which is the abbreviation for:
- CREATE
- READ / RETRIEVE
- UPDATE
- DELETE
2.2. SQL
2.2.1. CRUD
In SQL, the commands to perform each of these operations are:
- CREATE, INSERT
- E.g., to create a new table, we can use:
CREATE table (column type, ...);wheretableis the name of our new table, andcolumnis the name of a column, followed by its type. - SELECT
SELECT column FROM table;- UPDATE
- DELETE
We can check the schema of our new table with .schema:
We see that .import used the CREATE TABLE ... command listed to create a table called shows, with column names automatically copied from the CSV's header row and types assumed to be text.
We can select a column with:
- Notice that we capitalize SQL keywords by convention, and we'll see titles from our rows printed in the order from the CSV.
- We can also select multiple columns with
SELECT Timestamp, title FROM shows;, or all columns withSELECT * FROM shows;, where*is a wild card means all in SQL.
2.2.2. Functions
SQL supports many functions that we can use to count and summarize data:
AVGCOUNTDISTINCT, for getting distinct values without duplicatesLOWERMAXMINUPPER- ...
We can clean up our titles as before, converting them to uppercase and printing only the unique value:
2.2.3. Clauses
We can also add more clauses, or phrases that modify our query:
WHERE, matching results on a strict conditionLIKE, matching results on a less strict conditionORDER BY, ordering results in some wayLIMIT, limiting the number of resultsGROUP BY, grouping results in some way- ...
We can filter rows by titles:
But there are other entries we would like to catch, so we can use:
- The
%character is a placeholder for zero or more other characters.
We can even group the same titles together, and count the number of times they appear:
We can order by the counts:
- And if we add
DESCto the end, we could see the results in descending order.
With LIMIT 10 added as well, we see the top 10 rows:
Finally, we’ll trim whitespace from each title too, nesting that function:
2.2.4. Saving data
Before we finish, we’ll want to save our data into a file with .save shows.db, which we’ll see in our IDE after running that command.
Notice that our program to find the most popular shows from earlier, which took dozens of lines of code in Python, now only requires one (long) line of SQL.
We’ve used SQLite’s command-line interface, but there are also graphical programs that support working with SQL queries and viewing results more visually.
2.3. Tables
2.3.1. CRUD in a table
Our genres column has multiple genres in the same field, so we'll use LIKE to get all the titles containing some genres:
- But the genres are still stored in comma-separated list themselves, which is not as clean. E.g., if our genres included both “Music” and “Musical”, it would be difficult to select titles with just the “Music” genre.
We can insert data into a table manually with INSERT INTO table (column, ...) VALUES(value, ...);.
- For example, we can say:
We can update a row with UPDATE table SET column = value WHERE condition;, like:
We can even remove all rows that match with: DELETE FROM table WHERE condition;:
2.3.2. Design tables
Now let’s write our own Python program that will use SQL to import our CSV data into tables with the following design:
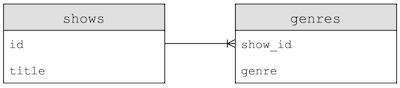
- This design will start to normalize our data, or reduce redundancy and ensure a single source of truth.
-
Here, for example, we have a table named
shows, with each show having anidandtitle, and another table,genre, which uses each’s show’sidto associate a genre with a show. Note that the show’stitledoesn’t need to be stored multiple times. -
We can also now add multiple rows in the
genretable, to associate a show with more than one genre.
2.3.3. Columns' data types in SQL
It turns out that SQL, too, has its own data types to optimize the amount of space used for storing data, which we’ll need to specify when creating a table manually:
BLOB, for "binary large object", raw binary data that might represents filesINTEGERNUMERIC, number-like but not quite a number, like a data or timeREAL, for floating-point valuesTEXT, like strings
2.3.4. Columns' Attributes in SQL
Columns can also have additional attributes:
NOT NULL, which specifies that there must be some valuesUNIQUE, which means that the value for that column must be unique for every row in that tablePRIMARY KEY, like theidcolumn above that will used to uniquely identify each rowFOREIGN KEY, like theshow_idcolumn above that refers to a column in some other table
2.3.5. SQL in Python
We’ll use the CS50 library’s SQL feature to make queries easily, and there are other libraries for Python as well:
- First, we’ll open a
shows.dbfile and close it, to make sure that the file is created. - Then, we’ll create a
dbvariable to store our database created bySQL, which takes the database file we just created. - Next, we’ll run SQL commands by writing it as a string, and calling
db.executewith it. Here, we’ll create two tables as we designed above, indicating the names, types, and properties of each column we want in each table. -
Now, we can read our original CSV file row by row, getting the title and using
db.executeto run anINSERTcommand for each row. It turns out that we can use the?placeholder in a SQL command, and pass in a variable to be substituted. Then, we’ll get back anidthat’s automatically created for us for each row, since we declared it to be a primary key. -
Finally, we’ll split the genre string in each row by the comma, and insert each of them into the
genrestable, using theidfor the show asshow_id.
After we run this program, we can see the IDs and titles of each show, as well as the genres where the first column is a show’s ID:
- Notice that the show with id 512, “GAME OF THRONES”, now has five genres associated with it.
2.3.6. Nested query
To find all the musicals, for example, we can run:
And we can nest that query to get titles from the list of show IDs:
- Our first query, in the parentheses, will be executed first, and then used in the outer query.
We can find all the rows in shows with the title of “THE OFFICE”, and find all the genres associated:
We could improve on the design of our tables even more, with a third table:

- Now, each genre’s name will only be stored once, with a new table, a join table, called
shows_genresthat contains foreign keys that link shows to genres. This is a many-to-many relationship, where one show can have many genres, and one genre can belong to many shows. - If we needed to change a genre’s name, we would only have to change one row now, instead of many.
2.3.7. Subtypes
It turns out that there are subtypes for a column, too, that we can be even more specific with:
INTEGERsmallint, with fewer bitsintegerbigint, with more bitsNUMERICbooleandatadatatimenumeric(scale, precision), with a fixed number of digitstimetimestampREALrealdouble precision, with twice as many bitsTEXTchar(n), a fixed number of charactersvarchar(n), a variable numbertext, a string with no limit
3. Indexes and JOIN
3.1. What is IMDb
IMDb, abbreviation for the Internet Movie Database, has datasets available for download as TSV (table-separated values) file.
3.2. Schema of IMDb
After we import one such dataset, we'll see tables with the following schemas:
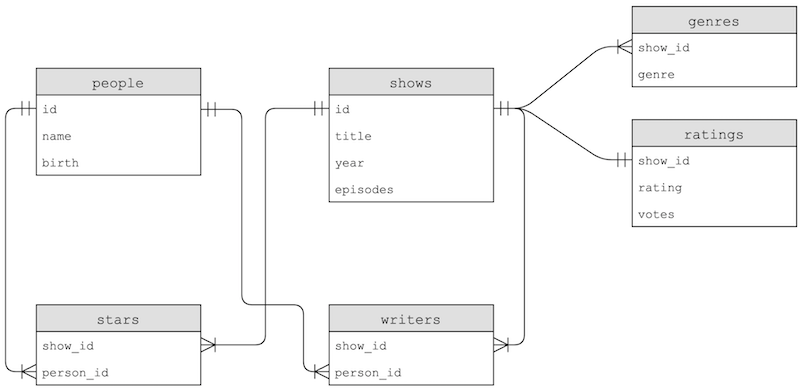
- The
genrestable has some duplication, since thegenrecolumn is repeated, but thestarsandwriterstable join rows in thepeopleandshowstable based on their relationship.
3.3. indexes
With SELECT COUNT(*) FROM shows; we can see that there are more than 150,000 shows in our table, so with a large amount of data we can use indexes, which tells our database program to create additional data structures so we can search and sort with logarithmic time:
- It turns out that these data structures are generally B-trees, like binary trees we've seen in C, with nodes organized such that we search faster than linearly.
- Creating an index takes some time, but afterwards we can run queries much more quickly.
3.4. Join
With our data spread among different tables, we can use JOIN commands to combine them in our queries:
- With the
JOINsyntax, we can virtually combine tables based on their foreign keys, and use their columns as though they were one table.
4. Problems
4.1. SQL injection attack
One problem in SQL is called a SQL injection attack, where someone can inject, or place, their own commands into inputs that we then run on our database.
Our query for logging a user in might be rows = db.execute("SELECT * FROM users WHERE username = ? AND password = ?", username, password). By using the ? placeholders, our SQL library will escape the input, or prevent dangerous characters from being interpreted as part of the command.
In contrast, we might have a SQL query that’s a formatted string, such as:
If a user types in malan@harvard.edu'--, then the query will end up being:
This query will actually select the row where username = 'malan@harvard.edu', without checking the password, since the -- turns the rest of the line into a comment in SQL.
4.2. Race conditions
Another problem with databases is race conditions, where code in a multi-threaded environment can be commingled, or mixed together, in each thread.
One example is a popular post getting lots of likes. A server might try to increment the number of likes, asking the database for the current number of likes, adding one, and updating the value in the database:
But for applications with multiple servers, each of them might trying to add likes at the same time. Two servers, responding to two different users, might get the same starting number of likes since the first line of code runs at the same time on each server. Then, both will set the same new number of likes, even though there should have been two separate increments.
To solve this problem, SQL supports transactions, where we can look rows in a database, such that a particular set of actions are guaranteed to happen together, with syntax like:
BEGIN TRANSACTIONCOMMITROLLBACK
E.g., we can fix our problem above with:
- The database will ensure that all the query in between are executed together.
Another example might be of two roommates and a shared fridge in their dorm. The first roommate comes home, and sees that there is no milk in the fridge. So the first roommate leaves to the store to buy milk, and while they are at the store, the second roommate comes home, sees that there is no milk, and leaves for another store to get milk as well. Later, there will be two jugs of milk in the fridge.
We can solve this problem by locking the fridge so that our roommate can’t check whether there is milk until we’ve gotten back.